Меня давно занимает вопрос атомарности типа int (да и любого типа, равного по длине шине процессора, например, указателя или float для x86).
Ясно, что в теории, нельзя полагаться на факт такой атомарности. Но давайте конкретизируем: платформа x86, и переменная объявлена как «volatile int a». Тут я не играюсь с «reinterpret_cast»’ом и приведением указателей, то есть можно гарантировать, что компилятор обеспечит правильное выравнивание, соответствующее шине процессора и памяти, тем самым гарантируя, что доступ к этой ячейке произойдет за один такт.
Есть ли хоть какой-то шанс с ненулевой вероятностью, что какое-то вычисление (команда процессора) по отношению к «а» может быть тут неатомарна? Может ли так быть, что операция «a++» или «a += arbitrary_stuff» и т.д. выполниться не целиком?
Так как переменная volatile, значит любые оптимизации будут компилятором запрещены, и не выйдет так, что вместо полноценной 32-х битной команды (обнуления, инкремента, умножения и т.д) компилятор использует, например, каскад двух 8-ми битных команд для операции, которую можно сделать одной 32-х битной.
Ведь где бы значение переменной «а» не обрабатывалось (в регистре, в кэше, в памяти), везде это будет та или иная одиночная команда процесса, которая, очевидно, атомарна.
Ясно, что правилом хорошего тона считается не полагаться на атомарность int’а. Но современная архитектура процессоров (микроконтроллеры пока не берем) практически гарантирует эту атомарность, разве нет?
Показаны сообщения с ярлыком приемчики. Показать все сообщения
Показаны сообщения с ярлыком приемчики. Показать все сообщения
понедельник, 27 декабря 2010 г.
четверг, 1 июля 2010 г.
Неконстантные ссылки в аргументах функций
У меня есть определенная позиция на использование неконстантных ссылок в С++ в аргументах функций – я стараюсь не использовать неконстантные ссылки для передачи аргументов, которые будут изменены внутри вызываемого блока.
Например, вместо:
void f(T& t) {
// change ‘t’
}
...
T a;
f(a);я предпочту передачу по указателю:
void f(T* t) {
// change ‘*t’
}
...
T a;
f(&a);Мой основной мотив – наглядность в вызывающем коде. Когда я вижу «&» перед аргументом, я точно знаю, что это возвращаемый параметр, и он может измениться после вызова. И мне не надо постоянно помнить, какие именно агрументы у этой функции ссылки, а какие нет.
Конечно тут есть и минусы: корявость текста в вызываемом коде, так как надо таскать за собой «*» или «->». Также неплохо бы проверять указатель на ноль.
А у вас есть предпочтения в этом вопросе?
суббота, 26 июня 2010 г.
Макросы для определения компилятора, библиотеки, операционной системы или архитектуры
Очень полезный проект - http://predef.sourceforge.net/.
В одном месте собрано большое количество макросов для определения компилятора, библиотеки, операционной системы, архитектуры и стандарта языка.
В одном месте собрано большое количество макросов для определения компилятора, библиотеки, операционной системы, архитектуры и стандарта языка.
воскресенье, 20 июня 2010 г.
fill_n vs memset
В данный момент на текущей работе я занимаюсь тем, что называется - высокоуровневое серверное программирование на С++. У меня уже есть все необходимые библиотеки низкого уровня и среднего (более того, если я отказываюсь по какой-то причине от готовой библиотеки, меня могут потом попросить это объяснить), и огромное количество библиотек высокого уровня, уровня бизнес-логики. К чему все это?
А вот к чему. Если разобраться, что я могу писать код вообще без С-шных штучек типа массивов, malloc/free, старого способа приведения типов, строчек с нулем на конце и т.д. Получается, что мой диалект С++ можно урезать на тему всего, что я перечислил. Просто убрать, и все.
И от этого будет только польза. Сколько ошибок потенциально я НЕ сделаю в арифметике указателей (ее просто не будет)? Вместо того, чтобы мотивировать человека "разумно использовать наследия С в С++", их надо просто выключить. Конечно, сразу сузится и круг решаемых задач, но мой, кстати, не самый узкий круг, можно покрыть таким вот урезанным в сторону "правильного" С++ диалектом С++.
Например, как мне кажется, функция memset() в мире С++ в целом годится разве что для обнуления. Использование какой-либо иной константы-заполнителя принципиально приближает нас к проблемам с памятью. Хотите, например, "эффективно" заполнить строку пробелами, и зарядите для этого memset(), а потом вам неожиданно придется работать с многобайтовыми кодировками, и этот пробел, записанный через memset(), может стать источником проблем.
Так что используйте алгоритм "fill_n()" вместо "memset()". Может быть неэффективен? Может, а может и нет. Зато уж точно безопасен с точки зрения типизации.
А вот к чему. Если разобраться, что я могу писать код вообще без С-шных штучек типа массивов, malloc/free, старого способа приведения типов, строчек с нулем на конце и т.д. Получается, что мой диалект С++ можно урезать на тему всего, что я перечислил. Просто убрать, и все.
И от этого будет только польза. Сколько ошибок потенциально я НЕ сделаю в арифметике указателей (ее просто не будет)? Вместо того, чтобы мотивировать человека "разумно использовать наследия С в С++", их надо просто выключить. Конечно, сразу сузится и круг решаемых задач, но мой, кстати, не самый узкий круг, можно покрыть таким вот урезанным в сторону "правильного" С++ диалектом С++.
Например, как мне кажется, функция memset() в мире С++ в целом годится разве что для обнуления. Использование какой-либо иной константы-заполнителя принципиально приближает нас к проблемам с памятью. Хотите, например, "эффективно" заполнить строку пробелами, и зарядите для этого memset(), а потом вам неожиданно придется работать с многобайтовыми кодировками, и этот пробел, записанный через memset(), может стать источником проблем.
Так что используйте алгоритм "fill_n()" вместо "memset()". Может быть неэффективен? Может, а может и нет. Зато уж точно безопасен с точки зрения типизации.
воскресенье, 13 июня 2010 г.
Перебор всех разбиений множества на два подмножества
Допустим, есть массив (вектор)
v, и надо перебрать все возможные варианты разделения его компонент на два непересекающихся подмножества.Если элементов множества немного, а именно - их количество умещается в разрядную сетку вашего компьютера, например, не более 32-х или 64-х, то есть элегантный способ организовать перебор следующим образом:
vector<int> v(20); // Исходное множество
// Всего вариантов будет: 2^(v.size())-1.
for (int i = 1; i < (1 << v.size()); ++i) {
vector<int> left, right;
for (int j = 0; j < v.size(); ++j) {
if ((i >> j) & 1)
left.push_back(v[j]);
else
right.push_back(v[j]);
}
// Текущий вариант множеств left и right готов для обработки.
...
}среда, 12 мая 2010 г.
Плавающая точка уплыла
Решал одну задачу на UVa Online Judge. Долго не мог найти проблему и проверял алгоритм.
На ТопКодере есть отличная статья на эту тему (часть 1 и часть 2). Все кратко и по делу.
Но все было гораздо проще. Как вы думаете, что должна выводить следующая программа?
#include <iostream>
#include <cmath>
using namespace std;
int main(int argc, char* argv[]) {
double f = 1.15;
int a = f * 100.0 + 0.1E-9;
int b = f * 100.0;
cout << "a = " << a << endl;
cout << "b = " << b << endl;
return 0;
}Я ожидал два числа 115.
Нет, у меня на VS2008 она печатает:
a = 115
b = 114Вот такие дела.
Update:
Кстати, если попробовать так:
#include <iostream>
#include <cmath>
using namespace std;
int main(int argc, char* argv[]) {
double f = 1.15;
int a = f * 100.0 + 0.1E-9;
int b = f * 100.0;
cout << "a = " << a << endl;
cout << "b = " << b << endl;
double f1 = 0.15;
int a1 = f1 * 100.0 + 0.1E-9;
int b1 = f1 * 100.0;
cout << "a1 = " << a1 << endl;
cout << "b1 = " << b1 << endl;
return 0;
}a = 115
b = 114
a1 = 15
b1 = 15На ТопКодере есть отличная статья на эту тему (часть 1 и часть 2). Все кратко и по делу.
пятница, 16 апреля 2010 г.
Можно ли memset'ить float и double?
В финансовой области постоянно приходится иметь дело с ценами, а цены удобно держать как float или double. Также финансовой сфере много старого когда, написанного на С или Фортране.
А в мире языке С практика инициализации структур нулем через memset является весьма распространенной и в целом не самой плохой практикой.
Вопрос: а что, если в структуре есть поля типа double или float. Что будет, если поля этих типов будут тупо забиты нулями, каково будет значение этих полей?
Для начала я проверил у себя на Солярисе и в Visual Studio 9 - все вроде нормально. После memset'а нулем и float и double тоже равны нулю.
Хотя в целом правильный ответ такой: если ваш компилятор гарантирует хранение вещественных чисел в форматe IEEE 754, то вы в безопасности. Если нет (стандарт языка не гарантирует, что должен использоваться именно IEEE 754), то могут быть неожиданности.
А в мире языке С практика инициализации структур нулем через memset является весьма распространенной и в целом не самой плохой практикой.
Вопрос: а что, если в структуре есть поля типа double или float. Что будет, если поля этих типов будут тупо забиты нулями, каково будет значение этих полей?
Для начала я проверил у себя на Солярисе и в Visual Studio 9 - все вроде нормально. После memset'а нулем и float и double тоже равны нулю.
Хотя в целом правильный ответ такой: если ваш компилятор гарантирует хранение вещественных чисел в форматe IEEE 754, то вы в безопасности. Если нет (стандарт языка не гарантирует, что должен использоваться именно IEEE 754), то могут быть неожиданности.
среда, 17 марта 2010 г.
Обмен двух переменных через XOR
Чтобы поменять местами значения двух целочисленных переменных кроме как через использование дополнительной переменной, можно сделать так:
Update: В комментариях подсказали грамотную ссылку по трюкам с битовой арифметикой.
a += b;
b = a - b;
a -= b;a ^= b ^= a ^= b;Update: В комментариях подсказали грамотную ссылку по трюкам с битовой арифметикой.
среда, 24 февраля 2010 г.
Печать контейнера с разделителями
Иногда, при печати содержимого контейнера хочется избежать ненужного хвостового разделителя.
Простейшее решение выглядит так:
#include <iostream>
#include <vector>
int main(int argc, char* argv[]) {
int a[] = { 1, 2, 3, 4, 5 };
std::vector<int> v(a, a + 5);
for (int i = 0; i < v.size(); ++i) {
std::cout << v[i];
if (i < v.size() - 1)
std::cout << ", ";
}
std::cout << std::endl;
return 0;
}Условие в теле цикла решает поставленную задачу, но контейнеры лучше обходить через итераторы, поэтому следующая попытка может выглятеть так:
#include <iostream>
#include <vector>
int main(int argc, char* argv[]) {
int a[] = { 1, 2, 3, 4, 5 };
std::vector<int> v(a, a + 5);
for (std::vector<int>::const_iterator i = v.begin(); i != v.end(); ++i) {
std::cout << *i;
if (v.end() - i > 1)
std::cout << ", ";
}
std::cout << std::endl;
return 0;Но такой подход не самый верный, ибо итераторы далеко не всех контейнеров поддерживают операцию вычетания. Например, при использовании std::list вместо std::vector будет ошибка компиляции (как, кстати, и для первого примера, но по другой причине). Поэтому правильнее было бы написать:
#include <iostream>
#include <vector>
int main(int argc, char* argv[]) {
int a[] = { 1, 2, 3, 4, 5 };
std::vector<int> v(a, a + 5);
typedef std::vector<int>::const_iterator iterator;
for (iterator i = v.begin(); i != v.end(); ++i) {
std::cout << *i;
if (std::distance<iterator>(i, v.end()) > 1)
std::cout << ", ";
}
std::cout << std::endl;
return 0;
}Шаблонный класс std::distance умеет рассчитывать расстояние между итераторами, и даже для тех, которые не поддерживают операции сложения и вычетания. Для таких итераторов будет делаться пошаговый обход от одного к другому для подсчета расстояния. На первый взгляд получается, что вычислительная сложность такого простого цикла будет уже не линейной, а квадратической. Еше надо таскать за собой описание типа дважды — чтобы создать итератор цикла и экземпляр std::distance. Например, Visual Studio 2008 требует указывать тип итератора для шаблона std::distance и не может "угадать" его из параметров (другие компиляторы могут вести себя иначе). Получается, на ровном месте навернули какую-то ерунду.
Но есть весьма элегантный способ, который позволяет и использовать итераторы, и сохранить линейную сложность алгоритма для контейнеров, которые не умеют эффективно вычислять расстояние между элементами (например, std::list), и писать красиво и компактно:
#include <iostream>
#include <vector>
int main(int argc, char* argv[]) {
int a[] = { 1, 2, 3, 4, 5 };
std::vector<int> v(a, a + 5);
for (std::vector<int>::const_iterator i = v.begin(); i != v.end(); ++i) {
std::cout << *i;
if (i != --v.end())
std::cout << ", ";
}
std::cout << std::endl;
return 0;
}Трюк с оператором "--" позволяет эффективно проверить на последний элемент контейнера.
среда, 6 января 2010 г.
Больше коммитов, хороших и разных
Как часто у вас бывает, когда после часов работы выясняется, что все беспробудно сломано и уже не поддается никакой отладке. И причем уже непонятно, где новый код, а где старый. И в этом случае надо доставать вчерашний бэкап и как-то выяснять, что вы тут напрограммировали.
А все было бы заметно проще, если бы в процессе любой длинной и сложной работы делались бы промежуточные коммиты в систему контроля версий — своеобразные реперные точки, по которым можно пошагово отследить изменения.
Когда же используется централизованная система контроля версий (SCM) многие люди не коммитят незаконченный код, ибо в подавляющем числе случаев работа ведется в ветке, которой пользуется еще кто-то. Закоммитишь сломанный код — услышишь слова радости в свой адрес из другого конца комнаты.
Создание же ветки (нужно, например, для отслеживания изменений при отладки конкретного бага) в централизованной SCM более менее событие. Многие конторы имеют свои правила и процедуры создания веток (именование, причины создания, порядок их удаления и т.д.). Все это можно понять, так как внесения изменений в любой ресурс общего пользования (коим являтся репозиторий централизованной SCM) должны подчиняться каким-то правилам, а иначе будет хаос, и никто не сможет работать.
Что делать если у вас используется централизованная SCM? Просто начните использовать любую из современных распределенных систем параллельно с основной централизованной. Для начала можно вообще не вдаваться в детали хитрой интеграции локальной распределенной SCM и централизованной для автоматизированного переноса коммитов туда-сюда (например, как p4-git для Git и Perforce), а делать все просто: просто коммитить процесс работы в вашу собственную локальную распределенную систему для удобства отслеживания микро изменений, а когда все готово — делать большой коммит на сервер.
Мне приходится работать параллельно с разными SCM, и они преимущественно централизованные (SVN, Perforce, ClearCase), и преимущественно правила коммитов и слияний между ветками очень жесткие и детально прописанные. А про создание собственных веток я уж и не говорю. Но это не мешает мне локально использовать git, в котором в дополнение к официальным веткам сидит десяток моих собственных, коммиты и слияние в которых я делаю десятки раз в день.
Я стараюсь коммитить как можно чаще. Например, добавил новый target в Makefile — коммит, добил новый тест (пусть даже он пока не компилируется толком) — коммит, заставил тест компилироваться — точно коммит, ну а заставил тест работать — стопудово коммит. Решил попробовать новый метод линковки проекта и для этого подкорячить Makefile — создал новую ветку, поигрался, слил результаты с основной веткой и удалил временную. Конец рабочего дня и пора лететь на купание дочки — коммит, даже если исходники представляют собой поле боя, так как завтра тебя с утра могут неожиданно перебросить на Умань чинить срочный баг, и потом уже точно не вспомнить, что там к чему.
Также желательно, чтобы коммиты были логически изолированы. Например, в запале ты исправил сетевую подсистему и добавил кнопку в UI — не стоит объединять все это в один коммит, так как может случиться, что вы заходите эту новую кнопку в параллельной версии, и если это отдельный коммит, то перенести его можно будет простым слиянием или cherry-pick'ом. Наличие staging area (индекса) в git позволяет легко коммитить выборочно (причем даже файл по кускам). Для Mercurial я нашел более менее похожую возможность в TortoiseHG, когда при коммите можно отметить файлы, которые в него включаются.
А так как каждый коммит требует словесного описания, то волей неволей это заставляет тебя оглядывать в целом, что ты тут понаписал. Для экстренных коммитов в конце дня, когда все может быть тотально сломано, а коммитить надо, то я обычно ставлю префикс "UNFINISHED: " в описание, по которому с утра сразу видно, что в исходниках может быть засада.
Лирическое отступление. С некоторого времени у меня даже всякие самопальные скрипты в UNIXе (а у кого их нет?) и конфигурационные файлы типа.profile,.Xdefaultsили.vimrcживут под контролем git'а. Другой пример: скачал я новыйgdb-7.0. Развернул, скомпилил. При работе он начал иногда падать на определенных машинах с ошибкой. Интернет сказал, что это известный баг и есть патч. Так вот: сначала сразу после разворачивания оригинального архива дерево исходников gdb помещается в git (git init && git add * && git commit -m "Original gdb-7.0."), а только затем делается патч и тоже коммитится в git. Для чего? Чтобы понимать, что изменено, когда и почему.
Еще одно лирическое отступление. Ни что так помогает понять, насколько "нужен" тебе некий домашний хлам, как его датирование. Записал DVD с бэкапом — кроме названия диска еще надо надписать дату записи. Собрал документы по сданному проекту в архивую папку — поставил дату. Потом, через N лет, этот стикер с датой однозначно решит судьбу предмета и, возможно, определит его в помойку, освободив место в шкафу. В компьютере все это далается еще проще. Ну а история изменений/версий только приятно автоматизируют процесс.
Культура повсеместного использования контроля версий крайне позитивна. А распределенные системы (типа Git, Mercurial или Bazaar) позволяют приобщиться к прекрасному даже если все вокруг вас не хотят (пока!) принять эту культуру.
Посты по теме:
четверг, 29 октября 2009 г.
Искусственная типизация однородных параметров в C++
Допустим есть вот такой класс:
Можно улучшить дизайн? Да.
Например, так:
Согласен, писанины немного больше, но зато полная гарантия от опечаток и, как следствие, глупых, но коварных ошибок.
Возражения есть?
class Date {
public:
Date(int year, int month, int day) {
...
}
};Date d(2009, 4, 5);Можно улучшить дизайн? Да.
Например, так:
class Year {
public:
explicit Year(int year) : year_(year) {}
operator int() const { return year_; }
private:
int year_;
};class Month { ... };
class Day { ... };Date может быть таким:class Date {
public:
Date(Year year, Month month, Day day);
Date(Month month, Day day, Year year);
Date(Day day, Month month, Year year);
}Date d(Year(2010), Month(4), Day(5));Date d(Month(4), Day(5), Year(2010));Согласен, писанины немного больше, но зато полная гарантия от опечаток и, как следствие, глупых, но коварных ошибок.
Возражения есть?
среда, 8 июля 2009 г.
Google C++ coding stantard прямо в Visual Studio
Многие читали стандарт кодирования на С++ от Google.
Для себя я его давно использую, а на работе удалось продавить его фрагменты в наш внутренний стандарт.
В качестве приятного бонуса Google раздает задорную утилитку cpplint, для быстрой проверки исходника на С++ на соответствие правилам и для генерации отчета, понимаемого средой разработки (например, Visual Studio). Написана она на Питоне, так что для ее использования его надо установить.
Я прикрутил
Итак,Menu->Tools->External Tool... , жмем
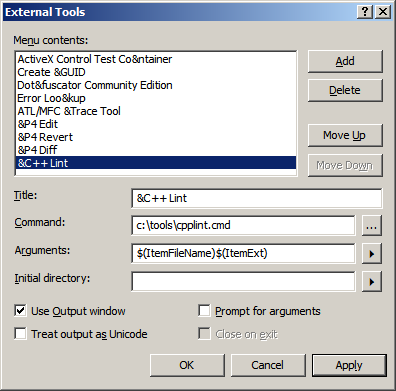
Теперь, прямо в редакторе жмем ALT-T,C,ENTER и снизу окне результатов получаем отчет. Кликая на его строки можно скакать по исходнику.
Лично я считаю, что порядок в исходниках напрямую связан с порядком в голове его автора.
Для себя я его давно использую, а на работе удалось продавить его фрагменты в наш внутренний стандарт.
В качестве приятного бонуса Google раздает задорную утилитку cpplint, для быстрой проверки исходника на С++ на соответствие правилам и для генерации отчета, понимаемого средой разработки (например, Visual Studio). Написана она на Питоне, так что для ее использования его надо установить.
Я прикрутил
cpplint себе в Студию, чтобы можно было проверять исходники прямо в редакторе.cpplint имеет несколько десятков checker'ов, их можно опционально отключать. Я отключил только три:- Проверку на использование
#includeбез указания относительного пути, например#include "one.h" #include "path/to/lib/one.h" - Проверку на формирование имени защитного
#define'а в начале заголовочного файла. У меня свое правило именования, и оно меня устраивает. - Проверку на неиспользование потоков в STL. Я потоки использую, поэтому отключил.
cpplint.cmd:C:\Python25\python.exe %~d0%~p0cpplint.py ^
--filter=-build/include,-build/header_guard,-readability/streams ^
--output=vs7 %1 %2 %3 %4 %5 %6 %7 %8 %9Итак,
Add и далее как на картинке (пути подправить по вкусу):
Теперь, прямо в редакторе жмем ALT-T,C,ENTER и снизу окне результатов получаем отчет. Кликая на его строки можно скакать по исходнику.
Лично я считаю, что порядок в исходниках напрямую связан с порядком в голове его автора.
вторник, 7 июля 2009 г.
Static assert
А какой у вас используется assert времени компиляции, если не использовать
У меня вот такой:
boost/static_assert.hpp У меня вот такой:
template <bool> struct STATIC_ASSERTION_FAILURE;
template <> struct STATIC_ASSERTION_FAILURE<true> {};
#define STATIC_CHECK(x) sizeof(STATIC_ASSERTION_FAILURE< (bool)(x) >)int main() {
STATIC_CHECK(sizeof(int) < sizeof(char));
return 0;
}понедельник, 6 июля 2009 г.
Скрипты для архивации проектов под Windows
Архивировать папку с проектом очень удобно и полезно. Для себя я давно выбрал следующий формат имен архивов: имя проекта + дата и время с точностью до секунды, например:
Последнее время я все чаще использую 7z как основной архиватор, но у него я не нашел схожего ключа на добавление в имя архива даты и времени. Пришлось слегка извратиться.
В этоге родился скрипт
Конечно, под UNIX'ом есть море путей сделать подобное, да и в Windows можно Cygwin использовать, но я всегда сначала пытаюсь сделать native решение, если это возможно.
easy-coding-2009.07.06-10.27.12.rarbackup.cmd:rem Берем имя родительского каталога без полного пути.
for %%I in (.) do set CWD=%%~nI
rem Архивируем.
winrar a -v -r -s -ag-YYYY.MM.DD-HH.MM.SS -x*.rar -x*.7z %CWD%Последнее время я все чаще использую 7z как основной архиватор, но у него я не нашел схожего ключа на добавление в имя архива даты и времени. Пришлось слегка извратиться.
В этоге родился скрипт
backup-7z.cmd @echo off
setlocal
set line=%DATE%
rem Проходимся по строке вида DD/MM/YYYY и
rem превращаем ее в YYYY.MM.DD.
:parse_date
for /F "delims=/ tokens=1,*" %%a in ("%line%") do (
set line=%%b
set now=%%a.%now%
)
if "%line%" neq "" goto parse_date
rem Отрезаем хвостовую точку от даты.
set now=%now:~0,10%
rem Добавляем время. Оно уже в формате HH:MM:SS.ms. Отрезаем доли секунды.
set now=%now%-%TIME:~0,8%
rem Заменяем двоеточие на точку
set now=%now::=.%
rem Берем имя родительского каталога без полного пути.
for %%I in (.) do set CWD=%%~nI
rem Архивируем.
7z a -mx9 -r -x!*.rar -x!*.7z %CWD%-%now%.7z
endlocalКонечно, под UNIX'ом есть море путей сделать подобное, да и в Windows можно Cygwin использовать, но я всегда сначала пытаюсь сделать native решение, если это возможно.
воскресенье, 17 мая 2009 г.
Список процессов в Windows
Писал я как-то один QA тест, и нужно мне было понять — выполнятся ли сейчас определенный процесс или нет, и если да, то с какой командной строкой. Естественно, нужно и для UNIX и для Windows.
В UNIX в порядке вещей просто вызвать команду
Для Windows же все оказалось чуть сложнее. Известная утилита
Я нашел вот такой способ. Через
Конечно, не так задорно, как через
В UNIX в порядке вещей просто вызвать команду
ps через popen() и распарсить текстовый вывод. Переносимо и надежно, так как для всех UNIXов ps всегда существует, и на этот факт можно положиться.Для Windows же все оказалось чуть сложнее. Известная утилита
pslist не является стандартной, и полагаться на нее опасно. Возиться с Windows API тоже не хотелось.Я нашел вот такой способ. Через
_popen() (аналог UNIXового popen()) можно вызвать вот такую команду:WMIC PROCESS get Caption,Commandline,ProcessidКонечно, не так задорно, как через
ps, но зато стандартно.
понедельник, 11 мая 2009 г.
Табуляция
Символы табуляции в исходниках — это бесконечное зло. А зло в квадрате, когда табуляция используется не только для отступов слева, но как разделитель (например, между аргументами функций, в теле блоков комментариев и т.д.). Ничего, кроме криков из другого конца комнаты типа "какая б... опять дописала кусок в моем неприкосновенном исходнике на С в Эклипсе, используя пробелы вместо табов, так что у меня тут в vi съехали все отступы?". И тут оба неправы. Первый в том, что не использовал тип отступов, принятый уже в существующем документе, а второй — в том, что использовал табуляцию изначально. Все шоколадно и солнечно, когда все сидят в Студии, но когда один использует vi, другой Студию, третий - FAR и т.д. (а это, увы, реалии много-платформенной разработки), то невозможно, чтобы все следовали правилу. Никто не любит соблюдать неудобные правила.
Лично я очень спокоен на тему стиля в целом и длины отступов в частности (лишь бы выглядело читабельно и соответствовало принятому для проекта соглашению), но вот табуляция — это как красная тряпка.
Ситуация усугубляется тем, что мы сопровождаем много кода, которому более двадцати лет, а тогда табуляция была еще ой как в ходу. Вот и приходится уговаривать людей проводить централизованные периодические зачистки кода от мусора прошлых лет, так как нет ничего хуже, когда человек совмещает смысловой коммит с "небольшими стилистическими правками", типа удаления табуляций, разбиения длинных строк и т.д. В целом, в этом не ничего плохого, но после таких "небольших правок" слияние веток становится кошмаром.
Лично я очень спокоен на тему стиля в целом и длины отступов в частности (лишь бы выглядело читабельно и соответствовало принятому для проекта соглашению), но вот табуляция — это как красная тряпка.
Ситуация усугубляется тем, что мы сопровождаем много кода, которому более двадцати лет, а тогда табуляция была еще ой как в ходу. Вот и приходится уговаривать людей проводить централизованные периодические зачистки кода от мусора прошлых лет, так как нет ничего хуже, когда человек совмещает смысловой коммит с "небольшими стилистическими правками", типа удаления табуляций, разбиения длинных строк и т.д. В целом, в этом не ничего плохого, но после таких "небольших правок" слияние веток становится кошмаром.
понедельник, 13 апреля 2009 г.
Задержка в одну секунду через time()
Иногда требуется сделать в программе цикл, работающий кратное секундам время. Есть множество способов для это.
Я предложу, как мне кажется, очень простой и очень переносимый способ.
Стандартная функция
Фрагмент кода, в котором рабочий цикл имеет условие, позволяющее ему работать время, близкое к одной секунде:
Тут, конечно, есть недостатки. Подготовительный цикл ожидания перехода на следующую секунду может "есть" процессорное время, если
В целом, такой прием дает рабочему циклу работать время, очень близкое к секунде.
Если знаете, как сделать еще проще — предлагайте.
Посты по теме:
Я предложу, как мне кажется, очень простой и очень переносимый способ.
Стандартная функция
time() возвращает так называемое UNIX-время в секундах. Проблема в том, что секунда, номер которой возвращает эта функция, может быть уже через пару микросекунд перейдет на следующую. Надо как-то "подравняться" к границе секунд.Фрагмент кода, в котором рабочий цикл имеет условие, позволяющее ему работать время, близкое к одной секунде:
...
// Получаем номер текущей секунды
time_t started = time(NULL);
// Ждем перехода на следующую секунду
while (time(NULL) == started);
// И сразу запускаем рабочий цикл
started = time(NULL);
do {
// Цикл, работающий в течение секунды
...
} while (time(NULL) == started);
...Тут, конечно, есть недостатки. Подготовительный цикл ожидания перехода на следующую секунду может "есть" процессорное время, если
time() для вашей системы не отдает time slice. Также сложно сделать какой-то надежный универсальный шаблон или макрос, так как надо гарантированно избежать какого-либо лишнего кода, чтобы не терять точность.В целом, такой прием дает рабочему циклу работать время, очень близкое к секунде.
Если знаете, как сделать еще проще — предлагайте.
Посты по теме:
воскресенье, 15 марта 2009 г.
Какой конструктор когда вызывается в С++
С++ имеет весьма разнообразный синтаксис для конструирования объектов. Надо признать, что порой этот синтаксис весьма неочевиден, и многие вещи надо просто знать, нежели догадаться, как они работают. Например:
class T {...};
...
T t = T(1);T вызвать конструктор по умолчанию (без аргументов), затем создать временный объект с помощью конструктора с одним аргументом и скопировать его в исходный объект перегруженным оператором копирования (или может конструктором копирования? ведь слева и справа объекты явно типа T...). К сожалению, тут невозможно просто догадаться по логике, тут надо знать, как это прописано в стандарте. Все эти "тонкости" конечно очевидны для профессионала, но у начинающих это порой вызывает непонимание, и как следствие использование однажды опробованных штампов "так работает" без какой-либо попытки что-то изменить.
Именно для таких случаев я обычно даю следующий пример, который покрывает часто используемые варианты создания объектов. Разобрав его один раз целиком, можно использовать его как подсказку в будущем, когда опять возникает вопрос "а что ж здесь будет вызвано: конструктор или оператор копирования?...".
Итак, файл ctor.cpp:
#include <iostream>
class T {
public:
T() { std::cout << "T()" << std::endl; }
T(int) { std::cout << "T(int)" << std::endl; }
T(int, int) { std::cout << "T(int, int)" << std::endl; }
T(const T&) { std::cout << "T(const T&)" << std::endl; }
void operator=(const T&)
{ std::cout << "operator=(const T&)" << std::endl; }
};
int main() {
std::cout << "T t1 : "; T t1;
std::cout << "T t2(1) : "; T t2(1);
std::cout << "T t3 = 1 : "; T t3 = 1;
std::cout << "T t4 = T(1) : "; T t4 = T(1);
std::cout << "T t5(1, 2) : "; T t5(1, 2);
std::cout << "T t6 = T(1, 2) : "; T t6 = T(1, 2);
std::cout << "T t7; t7 = 1 : "; T t7; t7 = 1;
std::cout << "T t8; t8 = T(1): "; T t8; t8 = T(1);
std::cout << "T t9(t8) : "; T t9(t8);
std::cout << "T t10 = 'a' : "; T t10 = 'a';
return 0;
}cl /EHsc ctor.cppT t1 : T()
T t2(1) : T(int)
T t3 = 1 : T(int)
T t4 = T(1) : T(int)
T t5(1, 2) : T(int, int)
T t6 = T(1, 2) : T(int, int)
T t7; t7 = 1 : T()
T(int)
operator=(const T&)
T t8; t8 = T(1): T()
T(int)
operator=(const T&)
T t9(t8) : T(const T&)
T t10 = 'a' : T(int)Также интересно, как был создана переменная t10. Видно, что для символьной константы компилятор "подобрал" наиболее подходящий конструктор. Неявным образом был вызвал конструктор от int. Если подобное поведение не входит в ваши планы, и вам совсем не нужно, чтобы конструктор от int вызывался, когда идет попытка создать объект от типа, который может быть неявно преобразован в int, например char, то можно воспользоваться ключевым словом explicit:
class T {
public:
...
explicit T(int) { std::cout << "T(int)" << std::endl; }
...
};
Вообще практика объявления любого конструктора с одним параметром со модификатором explicit является весьма полезной, и позволяет избежать некоторых неприятных сюрпризов, например, если вы хотели вызвать конструктор строки от типа char, предполагая создать строку, состоящую только из одного символа, а получилось, что этот класс не имеет такого конструктора. Зато есть конструктор от int, делающий совершенно не то, что вам нужно. Вот и будет сюрприз в виде символьной константы, истолкованной как целое число.
Я обычно по умолчанию пишу explicit для конструкторов с одним параметром, и очень редко приходится потом убирать этого слово. Тут как со словом const — сначала можно написать, а потом уже думать нужно ли тут его убрать или нет.
понедельник, 23 февраля 2009 г.
Голубая (Борланд) палитра для Visual Studio
В процессе перехода Visual Studio 2008 с Professional на Team System в очередной раз слетели настройки палитры. Так сложилось, годы работы на борланде приучили меня к голубому фону и желтым буквам, и ничего уже поделать нельзя. Как-то давно, покопав в интернете на тему разных палитр для Visual Studio, я пришел вот к такой трехшаговой комбинации, которая за минуту превращает стандартную микрософтовскую белую палитру в 90%-e подобие борландовой.
Menu -> Tools -> Options -> Environment -> Fonts and Colors:
Font -> Fixedsys
TextEditor:
Plain text -> Yellow/Navy
KeyWord -> Lime/(фон оставить по умолчанию)
Конечно, тут есть еще что доработать по мелочам, но лично мне и этого хватает.
А вот для чего я перешел с Professional на Team я расскажу буквально скоро.
Menu -> Tools -> Options -> Environment -> Fonts and Colors:
Font -> Fixedsys
TextEditor:
Plain text -> Yellow/Navy
KeyWord -> Lime/(фон оставить по умолчанию)
Конечно, тут есть еще что доработать по мелочам, но лично мне и этого хватает.
А вот для чего я перешел с Professional на Team я расскажу буквально скоро.
понедельник, 2 февраля 2009 г.
Функциональный деструктор в С++
В С++ крайне распространен прием использования класса
Например, вы размещаете в куче десяток объектов типа
std::vector для хранения указателей на размещенные в куче объекты.Например, вы размещаете в куче десяток объектов типа
Книга (Book) и сохраняете указатели на них в векторе:class Book {
public:
Book(int index);
...
};
...
std::vector<Book *> books;
for (int i = 0; i < 10; ++i)
books.push_back(new Book(i));for (std::vector<Book *>::iterator i = books.begin(); i != books.end(); ++i)
delete *ii здесь абсолютно неважна для цикла, она является чисто служебной. Все это, конечно, не так страшно, как использование оператора goto или статических переменных, но все равно хочется гармонии. И способ есть. Данный код можно переписать так:#include <algorithm>
...
class deleter {
public:
template <typename T>
void operator()(const T* p) const {
delete p;
}
};
...
std::for_each(a.begin(), a.end(), deleter());void operator()(...) является шаблонным. Затем стандартный алгоритм std::for_each() вызывает этот оператор для каждого члена вектора.Конечно, вы можете сказать, что мол битва за идею принуждает нас таскать за собой классСоглашусь, однако, что конкретно этот пример весьма тривиален и является в большинстве делом вкуса, нежели вопросом реального выигрыша простоте и тестируемости кода. Но сам прием весьма показателен в плане замены простейших алгоритмов высокоуровневыми сущностями. И еще, в защиту такого приему могу сказать, что например, вы можете переопределить алгоритмdeleter, но тут аргумент простой — данный подход ближе к декларативному подходу в программировании, нежели к прямому алгоритмическому. В декларативном подходе вы стараетесь как можно больше логики перенести из ее явного программирования базовыми конструкциями типа условий, циклов и т.д. к ее выражению через определения (декларации) сущностей и их взаимосвязей. Декларативные конструкции проще дробить на независимые куски, а значит проще тестировать. Например, вы можете протестировать алгоритмstd::for_eachв изоляции, тем самым гарантируя его корректную работу сразу во всей программе, а вот протестировать явный цикл в изоляции вряд ли получится, так как цикл "жестко вплетен" в прочую логику программы. Максимум удастся проверить данный конкретный цикл как-то вручную, и если их программе много, проверять придется каждый из них.
std::for_each на свой, который сможет на конкретно вашей платформе выполняться гораздо быстрее, или, например, ловить исключения работы с кучей и журналировать проблемы освобождения памяти. В случае же прямого использования цикла for вам придется переписать сам цикл. Хорошо, когда такое место одно в программе, а если их тысячи?
Подписаться на:
Сообщения (Atom)


